キャッシュの機構について考えてみた
2023.11.20
はじめに
アプリケーション開発において、しばしば同じデータへのリクエストが多く発生します。これは、クライアントからのリクエストに応じて、データベースにクエリを発行し、ほぼ同じ結果を繰り返し返却するという状況です。これは間違いではありませんが、データベースへの接続コストがパフォーマンスに少なからず影響を及ぼします。
より迅速なレスポンスを実現するためには、データベースにアクセスする代わりに、キャッシュデータをメモリ上に保持し、それを利用して応答する方法があります。このアプローチにより、データベースの負荷を軽減し、ユーザー体験を向上させることができます。
今回の記事では、このようなキャッシュを活用したシステムデザインについて考察し、その概要をポンチ絵と共にご紹介します。
システムデザイン
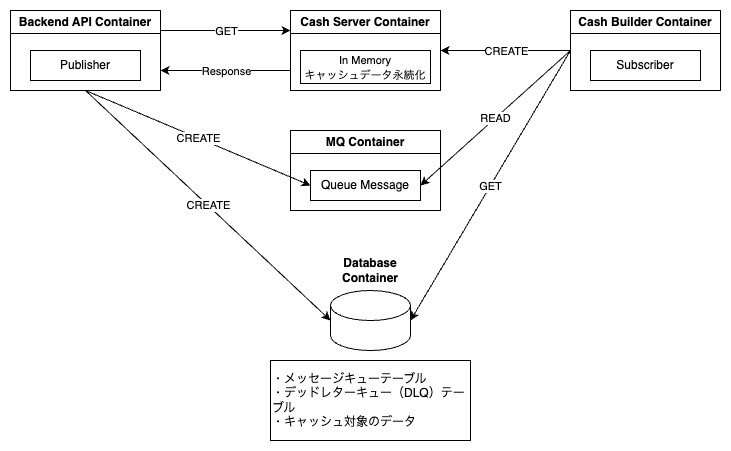
Backend API Container
キャッシュサーバー(Cash Server Container)からデータを取得する
クライアントからのリクエストを受領し、本来であればデータベースから取得したデータを返却しますが、キャッシュサーバーへ問い合わせをおこないデータを取得して返却します
Publisherの役割
そもそも、キャッシュサーバーで管理しているデータは、データベースに存在する特定のテーブルデータです。
そのため、該当のデータに変更があった場合には、キャッシュのデータへも反映する必要があるため、その場合にはメッセージキューとして、MQ Containerへメッセージを登録します。
MQ Container
キューメッセージを管理する役割です。
私は詳しくはありませんが、キャッシュの機構を実装する用途ではありませんでしたが、OSSではRabbitMQ、クラウドサービスではAWS SQSを選定してアプリケーションに取り入れたことがあります。
キャッシュサーバーとしての選定でもどちらを活用しても問題ないかと思います。
Cash Builder Container
Subscriberの役割
- メッセージキューを受領して、メッセージ内に記載されているキー情報をもとにデータベース(Database Container)へアクセスして目的のデータを取得し、キャッシュサーバー(Cash Server Container)にデータを更新します
- 正常終了
- メッセージキューテーブルの未処理データを処理済みにする(処理方式に左右されるが、未処理データは削除して、処理結果テーブルへデータを移動させる)
- MQ Containerのメッセージキューを処理済みにする
- 異常終了
- リトライを実施するも何らかの事情により、処理ができない場合には、メッセージキューテーブルからデッドレターキュー(DLQ)テーブルへデータを移動させてから次のデータを処理する
- DLQテーブルに移動させることで、未処理データの滞留を防ぐこと及び異常データとして調査がし易いようにするため
Cash Server Container
キャッシュデータを管理します。
OSSであれば、キーバリューでデータを保持できるRedisを活用することが多いです。
データはメモリ上(インメモリ)に保存するので、永続化させる設定をしないとコンテナの再起動時や停止時に消えてしまいますので注意が必要です。
おわりに
今回の記事では、イベント駆動型の設計となっております。
イベント駆動型のメリットには、リアルタイム処理ができることと効率的に処理ができる(ポーリングによる不必要なデータベースへのアクセス)ことが挙げられます。
一方でシステムの複雑性が増すことと難易度が上がりますので、実装するアプリケーションの規模と必要性やプロジェクト体制を鑑みた上で検討した方が良いと考えます。
イベント駆動型ではない方法としては、ポーリングでデータベースのメッセージキューテーブルに未処理データの存在を確認し、処理対象があればキャッシュデータを更新する制御を入れることもできます。
最後までお読みくださりありがとうございました。
はじめに
アプリケーション開発において、しばしば同じデータへのリクエストが多く発生します。これは、クライアントからのリクエストに応じて、データベースにクエリを発行し、ほぼ同じ結果を繰り返し返却するという状況です。これは間違いではありませんが、データベースへの接続コストがパフォーマンスに少なからず影響を及ぼします。
より迅速なレスポンスを実現するためには、データベースにアクセスする代わりに、キャッシュデータをメモリ上に保持し、それを利用して応答する方法があります。このアプローチにより、データベースの負荷を軽減し、ユーザー体験を向上させることができます。
今回の記事では、このようなキャッシュを活用したシステムデザインについて考察し、その概要をポンチ絵と共にご紹介します。
システムデザイン
Backend API Container
キャッシュサーバー(Cash Server Container)からデータを取得する
クライアントからのリクエストを受領し、本来であればデータベースから取得したデータを返却しますが、キャッシュサーバーへ問い合わせをおこないデータを取得して返却します
Publisherの役割
そもそも、キャッシュサーバーで管理しているデータは、データベースに存在する特定のテーブルデータです。
そのため、該当のデータに変更があった場合には、キャッシュのデータへも反映する必要があるため、その場合にはメッセージキューとして、MQ Containerへメッセージを登録します。
MQ Container
キューメッセージを管理する役割です。
私は詳しくはありませんが、キャッシュの機構を実装する用途ではありませんでしたが、OSSではRabbitMQ、クラウドサービスではAWS SQSを選定してアプリケーションに取り入れたことがあります。
キャッシュサーバーとしての選定でもどちらを活用しても問題ないかと思います。
Cash Builder Container
Subscriberの役割
- メッセージキューを受領して、メッセージ内に記載されているキー情報をもとにデータベース(Database Container)へアクセスして目的のデータを取得し、キャッシュサーバー(Cash Server Container)にデータを更新します
- 正常終了
- メッセージキューテーブルの未処理データを処理済みにする(処理方式に左右されるが、未処理データは削除して、処理結果テーブルへデータを移動させる)
- MQ Containerのメッセージキューを処理済みにする
- 異常終了
- リトライを実施するも何らかの事情により、処理ができない場合には、メッセージキューテーブルからデッドレターキュー(DLQ)テーブルへデータを移動させてから次のデータを処理する
- DLQテーブルに移動させることで、未処理データの滞留を防ぐこと及び異常データとして調査がし易いようにするため
- リトライを実施するも何らかの事情により、処理ができない場合には、メッセージキューテーブルからデッドレターキュー(DLQ)テーブルへデータを移動させてから次のデータを処理する
Cash Server Container
キャッシュデータを管理します。
OSSであれば、キーバリューでデータを保持できるRedisを活用することが多いです。
データはメモリ上(インメモリ)に保存するので、永続化させる設定をしないとコンテナの再起動時や停止時に消えてしまいますので注意が必要です。
おわりに
今回の記事では、イベント駆動型の設計となっております。
イベント駆動型のメリットには、リアルタイム処理ができることと効率的に処理ができる(ポーリングによる不必要なデータベースへのアクセス)ことが挙げられます。
一方でシステムの複雑性が増すことと難易度が上がりますので、実装するアプリケーションの規模と必要性やプロジェクト体制を鑑みた上で検討した方が良いと考えます。
イベント駆動型ではない方法としては、ポーリングでデータベースのメッセージキューテーブルに未処理データの存在を確認し、処理対象があればキャッシュデータを更新する制御を入れることもできます。
最後までお読みくださりありがとうございました。